We were hosting our final demo day, an event that has attracted significant public and investor attention. As the live stream begins and announcements are distributed across multiple channels, a large number of users attempt to access the platform simultaneously.
Under normal conditions, the system operates under a predictable and well-understood load profile. However, within minutes of the broadcast going live, traffic increases sharply, reaching a 10× surge relative to baseline usage. This sudden shift pushes the system beyond its typical operating envelope.
Editorial context:
Build Roulette documents production-informed decisions based on a combination of direct experience and observed industry patterns. Specific details are representative, not exhaustive.
Monitoring dashboards begin to surface stress indicators. CPU utilization approaches 95%, database connection pools near exhaustion and request latency steadily increases across critical application paths. A platform that was stable moments earlier is now operating close to failure thresholds.
This situation represents a real-world burst scenario. It is not a synthetic load test or a planned capacity exercise, but a genuine production event where user demand changes faster than infrastructure can react. In these moments, engineering decisions must be made quickly to prevent cascading failures and service downtime.
To respond effectively to this type of surge, engineering teams typically evaluate two primary scaling strategies:
- Vertical Scaling (Scaling Up)
- Horizontal Scaling (Scaling Out)
This article examines how each approach behaves under extreme, short-lived traffic spikes, the operational and cost trade-offs involved and how to determine the most appropriate strategy or combination of strategies to maintain system reliability during high-visibility events.
Assumptions This evaluation assumes a cloud-native AWS environment with a stateless application tier, managed database services, existing observability and the ability to modify instance types or Auto Scaling policies during planned or unplanned traffic surges.
1. VERTICAL SCALING: THE IMMEDIATE CAPACITY EXPANSION
When a high-visibility event triggers a sudden increase in demand, the most direct engineering response is often vertical scaling, commonly referred to as scaling up. Rather than introducing additional servers, vertical scaling increases the capacity of existing infrastructure by upgrading CPU, memory, or storage resources.
This approach allows a single instance to process a higher volume of requests within the same architectural footprint. From an operational perspective, it is often the fastest way to create additional headroom during an active incident.

EVALUATING THE BURST RESPONSE
The primary advantage of vertical scaling during a live surge is its low operational complexity. Because the architecture remains unchanged, no new load-balancing logic, service discovery mechanisms, or inter-node coordination is required.

- Speed of Relief: Scaling up provides immediate access to additional compute resources. A larger instance can absorb higher concurrency levels without waiting for new servers to be provisioned or warmed up.
- Data Simplicity: For stateful components such as relational databases, vertical scaling is typically the most straightforward way to increase capacity without introducing data consistency risks or replication complexity.
At peak capacity, a vertically scaled instance can sustain substantial throughput on its own. However, this approach introduces important cost considerations and hard scalability limits.

COST CONSIDERATIONS: PERFORMANCE VS. ECONOMICS
When evaluating vertical scaling, cost analysis must go beyond the hourly price of a larger instance. For burst-heavy workloads, AWS Burstable Performance Instances (T-family) are commonly used, operating on a CPU credit model.
- The Breakeven Threshold: For instances such as t3.large, cost efficiency begins to degrade once sustained average CPU utilization approaches ~42.5%, depending on region, pricing model and workload characteristics.
- Unlimited Mode Costs: When Unlimited Mode is enabled, AWS charges for surplus CPU credits (for example, approximately $0.05 per vCPU-hour for Linux). Under sustained high utilization, this can quickly exceed the cost of fixed-performance instances such as M5 or M6i, reducing the economic advantage of burstable instances.
- Efficiency Gains: In some cases, upgrading to a more powerful instance class allows compute-intensive workloads to complete faster, resulting in fewer total instance-hours consumed compared to a smaller, constantly saturated instance.
PRODUCTION CONSTRAINTS
Despite its speed and simplicity, vertical scaling has clear limitations under extreme burst conditions:
- Downtime Risk: Instance resizing often requires a stop-and-start operation. During a live event, even brief downtime can result in significant user drop-off and reputational impact.
- The Hardware Ceiling: Vertical scaling is bounded by the largest available instance types like the u-24tb1.metal (24 TB RAM) or c5d.metal (96 vCPUs). Once these limits are reached, no further scaling is possible without architectural changes.
 Vertical scaling is highly effective for immediate relief, but if a burst transitions into sustained demand, cost inefficiencies and hardware ceilings will eventually necessitate scaling out.
Vertical scaling is highly effective for immediate relief, but if a burst transitions into sustained demand, cost inefficiencies and hardware ceilings will eventually necessitate scaling out.
2. HORIZONTAL SCALING: DISTRIBUTED CAPACITY
While vertical scaling focuses on strengthening a single node, horizontal scaling, or scaling out, takes a fundamentally different approach. Instead of relying on one powerful machine, the system adds more identical nodes and distributes traffic across them.
This strategy aligns closely with modern cloud-native design principles and is the foundation of high-availability architectures.

EVALUATING THE BURST RESPONSE
Horizontal scaling is designed to handle unpredictable, high-volume traffic spikes that exceed the capacity of any single machine.

- Failure Resilience: Because the workload is distributed across multiple machines, the system significantly reduces single points of failure. By distributing workload across multiple instances, the system reduces single points of failure. If one node fails under load, remaining healthy nodes continue serving traffic.
- Elastic Growth: Unlike vertical scaling, which is constrained by hardware limits, horizontal scaling can expand as long as additional instances can be provisioned using Auto Scaling Groups (ASG). This provides a much higher theoretical ceiling for growth.

BUSINESS PERSPECTIVE: COST AND ELASTICITY
From a financial standpoint, horizontal scaling offers a more granular approach to cost control.
- Pay-As-You-Go Efficiency: With EC2 Auto Scaling, capacity can scale in automatically once traffic subsides. This prevents long-term overprovisioning after a short-lived event.
- Use of Spot Instances: Distributed fleets can incorporate Spot Instances to reduce cost significantly. Because the workload is spread across many nodes, occasional interruptions have minimal impact when properly architected.
- • Operational Overhead: Horizontal scaling introduces additional complexity. Load balancers, health checks, networking and distributed monitoring require more engineering effort than single-instance deployments.
PRODUCTION CONSTRAINTS
Horizontal scaling introduces its own challenges during sudden bursts:
- "Cold-Start" Latency: New instances require time to launch, initialize and pass health checks. If the surge is extremely sudden, existing capacity may be overwhelmed before new instances become available.
- Load Balancing Dependency: Effective scaling out requires a properly configured load balancer, adding a small but unavoidable layer of latency and cost.

- Database Bottleneck: While application servers can scale horizontally, databases are significantly harder to scale horizontally without architectural changes. Without mitigations such as read replicas or connection pooling, scaling out can shift the bottleneck to the data tier.
Horizontal scaling is the preferred strategy for long-term reliability, but its effectiveness during a burst depends on how quickly infrastructure can react.
3. DIAGONAL SCALING: COMBINING SPEED AND RESILIENCE
In high-pressure scenarios such as live broadcasts, choosing between vertical and horizontal scaling is often a false dilemma. Many production systems rely on a hybrid approach commonly referred to as diagonal scaling.
Diagonal scaling combines the immediate relief of vertical scaling with the resilience and elasticity of horizontal scaling.

THE DIAGONAL WORKFLOW
- Immediate Capacity Expansion (Vertical):: Prior to or at the onset of the event, core instances are upgraded to a more powerful class to create instant headroom and avoid cold-start delays tier (e.g., moving from a t3.medium to a c5.xlarge).
- Fleet Replication (Horizontal): Once utilization reaches predefined thresholds (like the ~42.5% breakeven point), Auto Scaling replicates the optimized instance across multiple Availability Zones to absorb continued growth.
This approach provides rapid response while maintaining a high ceiling for sustained demand.

EXAMPLE CONFIGURATION (SIMPLIFIED)
- Base instance: c5.xlarge (right sized for sustained efficiency).
- Auto Scaling Group: Minimum 2, Maximum 20 across multiple Availability Zones (AZs).
- Scaling trigger: CPU utilization > 60% for 2 minutes.
- Database protection: RDS Proxy enabled prior to scale-out.
PROTECTING THE DATA TIER
Even the most resilient application tier can fail if the database is overwhelmed during a connection surge.
- Amazon RDS Proxy: : RDS Proxy maintains a pool of established connections, shielding the database from connection storms as new application instances spin up.
- Edge Caching: Using services such as Amazon CloudFront to cache static and frequently accessed content can offload a significant portion of traffic from the application entirely.
These measures ensure that scaling strategies focus on dynamic workloads rather than unnecessary database pressure.
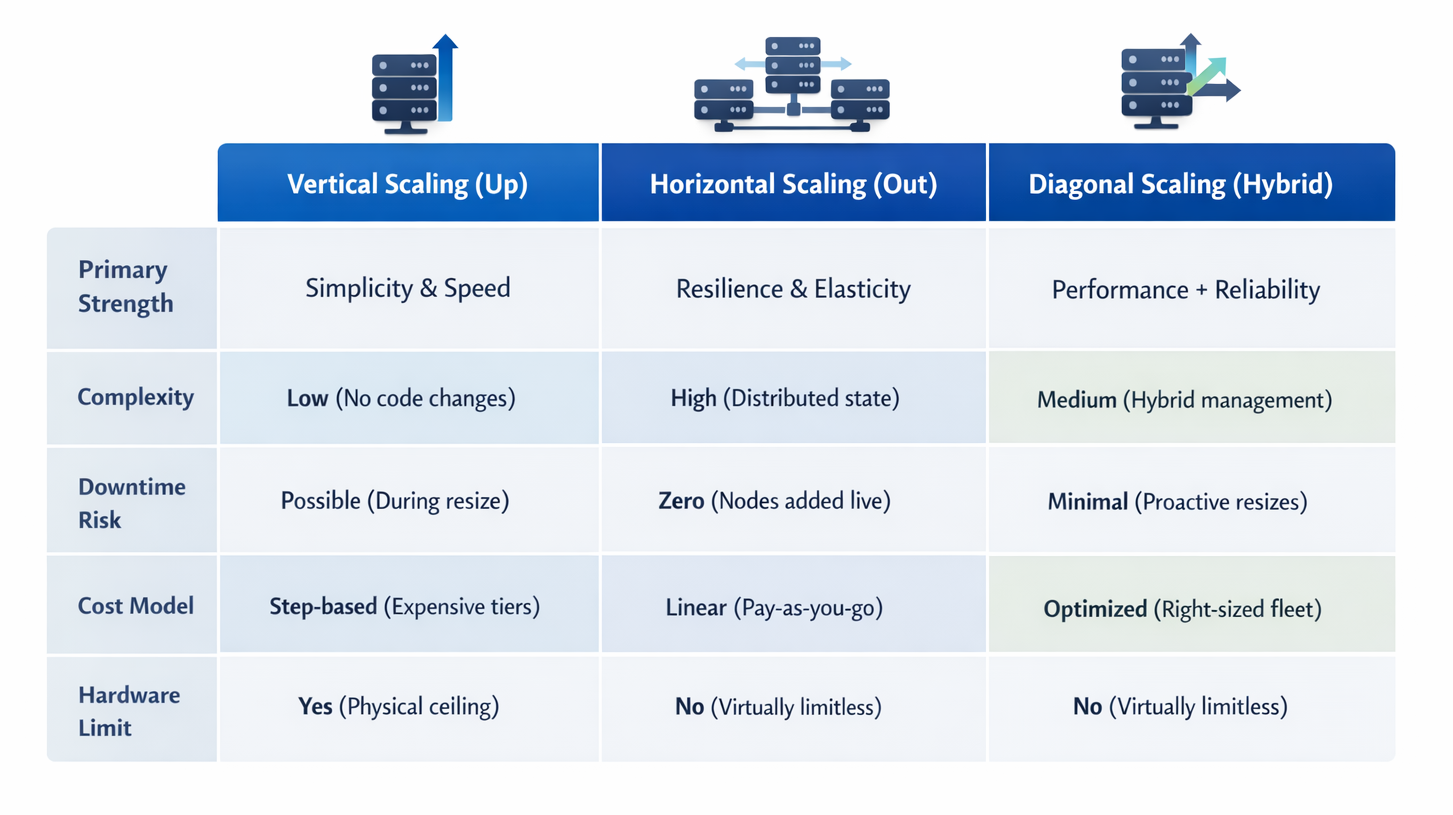
4. COMPARATIVE ANALYSIS: EVALUATING SCALING TRADE-OFFS
The team evaluated these strategies against three core drivers: Latency, Resilience, and Complexity. While vertical scaling addresses latency through immediate power, horizontal scaling provides long-term resilience. The primary technical challenge identified was the "Reaction Gap", the time between a traffic spike and the infrastructure's ability to respond.
SCALING STRATEGY COMPARISON
5. THE STRATEGIC CHOICE
For the "Final Demo Day" event, Roulette Investment explicitly chose a Diagonal Scaling strategy. This decision was driven by the need for zero downtime during the broadcast and a lean engineering team that could not afford to manage complex manual interventions at the height of the surge.
How the Problem was Solved?
Phase 1
Proactive Vertical Headroom: Thirty minutes before the live stream, the core application nodes were vertically scaled from t3.medium to c5.xlarge instances. This provided immediate "compute insurance" against the initial wave of traffic, bypassing the Cold-Start Latency of horizontal scaling.
Phase 2
Automated Horizontal Elasticity: An Auto Scaling Group (ASG) was configured with a minimum of 4 and a maximum of 20 instances, triggered when CPU utilization exceeded 60%. Once the vertical nodes reached their efficiency limit (the ~42.5% breakeven point), the system automatically replicated the optimized fleet to absorb the millions of simultaneous hits.
Phase 3
Database Decoupling: To prevent a Database Bottleneck, Amazon RDS Proxy was enabled. This shielded the database from "connection storms" as the application fleet expanded, allowing the data tier to remain stable while the web tier grew.
Why This Balance Worked:
- Operational Clarity: The team had a clear "pre-flight" checklist, reducing the risk of human error during the live event.
- Cost Control: By using Spot Instances for the horizontal fleet, the company reduced its surge-related compute costs by nearly 70% compared to a purely on-demand vertical strategy.
- User Experience: The combined approach resulted in Zero Downtime and consistent request latency throughout the 10x surge.
Engineering is the art of choosing the right trade-offs at the right time. For Roulette Investment, the "right-sized" architecture was not the most complex one, but the one that guaranteed a successful launch under the most intense scrutiny.
When the spotlight is on, infrastructure should be the last thing engineers have to worry about.